
Language technologies, particularly large language models (LLMs), often reproduce and amplify stereotypes leading to discriminatory outcomes. While research on fairness in these technologies has grown significantly, it has predominantly focused on Global North cultures and languages, especially English. Most bias detection methods rely on English-specific characteristics that don’t translate well to other languages, such as Spanish, where gender-neutral words are less common and cultural contexts differ substantially.
To address this gap, members of our team from the Universidad Nacional de Cordoba, including Luciana Benotti and Guido Ivetta, have developed EDIA (Stereotypes and Discrimination in Artificial Intelligence), a tool designed to empower Latin American social scientists and domain experts to detect biases in language models without requiring advanced technical skills.
Through workshops across multiple Latin American countries, EDIA has enabled experts from diverse backgrounds to identify and formalise culture-specific biases in language technologies. The project aims to promote widespread adoption of bias assessment in Latin America by building culturally relevant datasets representing stereotypes, developing programming libraries to integrate these datasets into audit processes, and creating educational materials for replication in other languages and contexts.
For more details on our research, please visit our published study at https://dl.acm.org/doi/full/10.1145/3653322.
🇦🇷 Spanish
Las tecnologías del lenguaje, particularmente los modelos de lenguaje de gran escala (LLMs), suelen reproducir y amplificar estereotipos que conducen a resultados discriminatorios. Si bien la investigación sobre equidad en estas tecnologías ha crecido significativamente, se ha centrado predominantemente en culturas e idiomas del Norte Global, especialmente el inglés. La mayoría de los métodos de detección de sesgos se basan en características específicas del inglés que no se traducen bien a otros idiomas, como el español, donde las palabras de género neutro son menos comunes y los contextos culturales difieren sustancialmente.
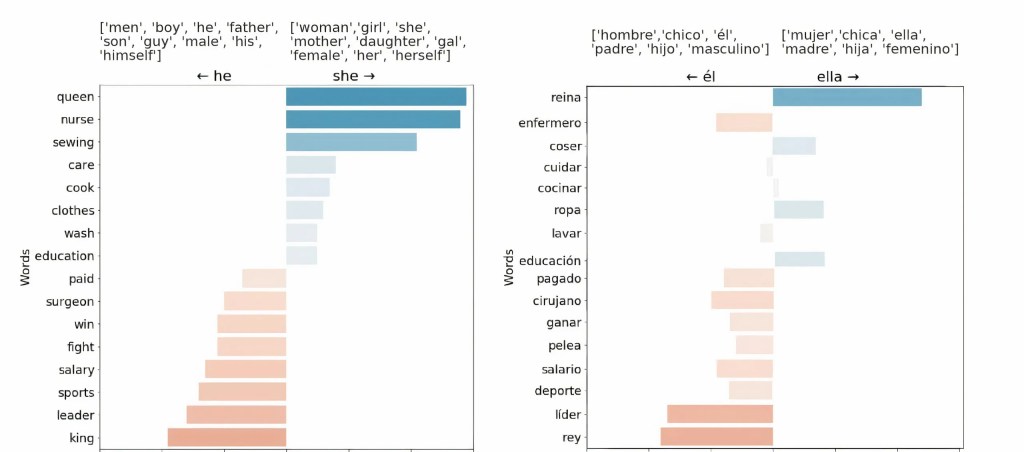
Una lista de 16 palabras en inglés (izquierda) y su traducción al español (derecha) y la similitud de sus embeddings de palabras con respecto a conceptos masculinos y femeninos. Esta figura ilustra que las metodologías para la detección de sesgos desarrolladas para el inglés no son directamente aplicables a otros idioma
Para abordar esta brecha, miembros de nuestro equipo de la Universidad Nacional de Córdoba han desarrollado EDIA (Estereotipos y Discriminación en Inteligencia Artificial), una herramienta diseñada para empoderar a científicos sociales y expertos de dominio latinoamericanos en la detección de sesgos en modelos de lenguaje sin requerir habilidades técnicas avanzadas.
A través de talleres realizados en varios países latinoamericanos, EDIA ha permitido que expertos de diversos ámbitos identifiquen y formalicen sesgos culturales específicos en tecnologías del lenguaje. El proyecto busca promover la adopción generalizada de evaluaciones de sesgo en América Latina mediante la construcción de conjuntos de datos culturalmente relevantes que representen estereotipos, el desarrollo de bibliotecas de programación para integrar estos conjuntos de datos en procesos de auditoría, y la creación de materiales educativos para su replicación en otros idiomas y contextos.
Para más detalles sobre nuestra investigación, visitá nuestro estudio publicado en https://dl.acm.org/doi/full/10.1145/3653322.

Leave a comment